
Content
- Preparació del vostre conjunt de dades
- Reclameu la prova gratuïta de Google Cloud Platform
- Creeu un nou projecte de GCP
- Habiliteu les API automàtiques i d'emmagatzematge al núvol
- Creeu un cub d'emmagatzematge al núvol
- Hora d'entrenament: creació del vostre conjunt de dades
- Formació del vostre model d’aprenentatge automàtic
- Com de precisa és el vostre model?
- Posa a prova el teu model.
- Embalatge
L’aprenentatge automàtic (ML) és el concepte de sondeig de ciència-ficció dels ordinadors que s’ensenyen. A ML, proporcioneu algunes dades que representen el tipus de contingut que voleu que el model d'aprenentatge automàtic processi automàticament, i el model s'ensenya a partir d'aquestes dades.
L’aprenentatge de màquines pot ser d’avantguarda, però també té enorme barrera a l’entrada. Si voleu utilitzar qualsevol tipus de ML, normalment haureu de contractar un expert en aprenentatge de màquines o un científic de dades. Ambdues professions actualment tenen una gran demanda.
Cloud AutoML Vision de Google és un nou servei d’aprenentatge automàtic que té com a objectiu acostar ML a les masses permetent crear un model d’aprenentatge automàtic, encara que tinguis zero experiència ML. Mitjançant Cloud AutoML Vision, podeu crear un model de reconeixement d’imatges capaç d’identificar contingut i patrons a les fotografies i, a continuació, utilitzar aquest model per processar les imatges posteriors automàticament.
Aquest tipus de ML basat en visuals es pot utilitzar de moltes maneres diferents. Voleu crear una aplicació que proporcioni informació sobre una fita, producte o codi de barres en què l’usuari estigui apuntant el seu telèfon intel·ligent? O voleu crear un potent sistema de cerca que permeti als usuaris filtrar milers de productes en funció de factors com el material, el color o l'estil? Cada cop més, l’aprenentatge automàtic és una de les maneres més eficaces d’oferir aquest tipus de funcionalitats.
Tot i que encara està en versió beta, ja podeu utilitzar Cloud AutoML Vision per crear models personalitzats d’aprenentatge que identifiquin patrons i contingut a les fotos. Si esteu desitjosos de descobrir de què tracta tot el buzz machine learning, aleshores en aquest article us mostraré com crear el vostre propi model de reconeixement d’imatges i, a continuació, l’utilitzaré per processar fotografies noves automàticament.
Preparació del vostre conjunt de dades

Quan treballeu amb Cloud AutoML, fareu servir fotografies etiquetades com a conjunts de dades. Podeu utilitzar qualsevol foto o etiqueta que us agradi, però per ajudar-lo a mantenir aquest tutorial senzill, crearé un model senzill que pugui distingir entre fotos de gossos i fotos de gats.
Independentment de les particularitats del vostre model, el primer pas és l'obtenció d'algunes fotos adequades.
Cloud AutoML Vision requereix almenys 10 imatges per etiqueta o 50 per a models avançats, per exemple, en models on seran diverses etiquetes per imatge. Tanmateix, com més dades proporcioneu, més alt és la possibilitat que el model identifiqui correctament contingut posterior, de manera que els documents de la Visió AutoML recomanen que utilitzeu al menys 100 exemples per model. També heu de proporcionar aproximadament el mateix nombre d’exemples per etiqueta, ja que una distribució injusta animarà el model a mostrar tendència cap a la categoria més “popular”.
Per obtenir els millors resultats, les imatges d’entrenament han de representar la varietat d’imatges que toparà amb aquest model, per exemple, potser haureu d’incloure imatges realitzades en diferents angles, a resolucions més altes i inferiors i amb diferents antecedents. AutoML Vision accepta imatges en els formats següents: JPEG, PNG, WEBP, GIF, BMP, TIFF i ICO, amb una mida màxima de fitxer de 30 MB.
Com que només experimentem amb el servei Cloud AutoML Vision, és probable que vulgueu crear un conjunt de dades el més ràpidament i fàcilment possible. Per ajudar a mantenir les coses senzilles, descarregaré un munt de fotografies gratuïtes de gossos i gats de Pexels i, a continuació, emmagatzemaré les fotos de gats i gossos en carpetes separades, ja que facilitarà la possibilitat de penjar-les més endavant.
Tingueu en compte que quan es construeixen conjunts de dades per utilitzar-los en producció, heu de tenir en compte les pràctiques d’IA responsables per ajudar a prevenir un tractament perjudicial. Per obtenir més informació sobre aquest tema, consulteu els documents de la Guia ML inclusiva de Google i les pràctiques d’IA responsable de Google.
Hi ha tres maneres de penjar les dades a AutoMl Vision:
- Carregueu les imatges ja ordenades a les carpetes que corresponen a les vostres etiquetes.
- Importeu un fitxer CSV que contingui les imatges, a més de les seves etiquetes de categories associades. Podeu penjar aquestes fotos des del vostre equip local o des de Google Cloud Storage.
- Carregueu les imatges mitjançant la interfície d'usuari de Google Cloud AutoML Vision i, a continuació, apliqueu etiquetes a cada imatge. Aquest és el mètode que utilitzaré en aquest tutorial.
Reclameu la prova gratuïta de Google Cloud Platform
Per utilitzar Cloud AutoML Vision, necessitareu un compte de Google Cloud Platform (GCP). Si no teniu cap compte, podeu registrar-vos a una prova gratuïta de dotze mesos dirigint-vos a la pàgina de prova de Cloud Cloud de forma gratuïta i seguint les instruccions. Vostè voluntat heu d’introduir els detalls de la vostra dèbit o de la vostra targeta de crèdit, però, segons les preguntes freqüents de nivell gratuït, només s’utilitzen per verificar la vostra identitat i no se us farà cap càrrec, tret que actualitzeu a un compte de pagament.
L’altre requisit és que heu d’habilitar la facturació per al vostre projecte AutoML. Si només us heu registrat per a una prova gratuïta o no teniu informació de facturació associada al vostre compte GPC, aleshores:
- Dirigiu-vos a la consola GCP.
- Obriu el menú de navegació (la icona alineada a la part superior esquerra de la pantalla).
- Seleccioneu "Facturació".
- Obriu el menú desplegable "La meva facturació", seguit de "Gestiona els comptes de facturació".
- Seleccioneu "Crea un compte" i, a continuació, seguiu les instruccions que apareixen a la pantalla per crear un perfil de facturació.
Creeu un nou projecte de GCP
Ja esteu preparat per crear el vostre primer projecte de Cloud AutoML Vision:
- Dirigiu-vos a la pàgina Gestiona recursos.
- Feu clic a "Crea el projecte".
- Poseu un nom al vostre projecte i, a continuació, feu clic a "Crea".
Si teniu diversos comptes de facturació, GCP hauria de preguntar-vos a quin compte voleu associar amb aquest projecte. Si teniu un compte de facturació únic i sou l’administrador de facturació, i aquest compte s’enllaçarà automàticament amb el vostre projecte.
També podeu seleccionar un compte de facturació manualment:
- Obriu el menú de navegació de la consola GCP i, a continuació, seleccioneu "Facturació".
- Seleccioneu "Enllaça un compte de facturació".
- Seleccioneu "Configura el compte" i, a continuació, escolliu el compte de facturació que vulgueu associar a aquest projecte.
Habiliteu les API automàtiques i d'emmagatzematge al núvol
Quan creeu el vostre model, emmagatzemareu totes les vostres imatges de formació en un cub d'emmagatzematge al núvol, per la qual cosa haurem d'habilitar el format automàtic i API de Google Cloud Storage:
- Obriu el menú de navegació de GCP i seleccioneu "API i serveis> Tauler de control".
- Feu clic a "Activa les API i serveis".
- Comenceu a escriure "API AutoML núvol" i, a continuació, seleccioneu-lo quan aparegui.
- Trieu "Activa".
- Vés a la pantalla "API i serveis> Tauler de control> Activa les API i serveis".
- Comenceu a escriure "Google Cloud Storage" i seleccioneu-lo quan aparegui.
- Trieu "Activa".
Creeu un cub d'emmagatzematge al núvol
Crearem el nostre cub d'emmagatzematge al núvol mitjançant Cloud Shell, que és una màquina virtual basada en Linux en línia:
- Seleccioneu la icona "Activa Google Cloud Shell" de la barra de capçalera (on es troba el cursor a la captura de pantalla següent).
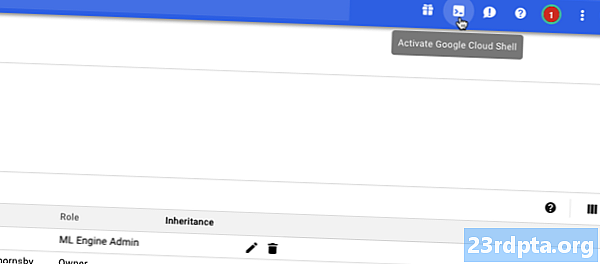
- Una sessió de Cloud Shell s’obrirà al llarg de la part inferior de la consola. Espereu mentre Google Cloud Shell es connecta al vostre projecte.
- Copieu / enganxeu la següent comanda a Google Cloud Shell:
PROJECT = $ (projecte de valor de configuració de gcloud) && BUCKET = "$ {PROJECT} -vcm"
- Premeu la tecla "Enter" del teclat.
- Copieu / enganxeu la següent comanda a Google Cloud Shell:
gsutil mb -p $ {PROJECT} -c regional -l us-central1 gs: // $ {BUCKET}
- Premeu la tecla "Enter".
- Concediu el permís del servei AutoML per accedir als vostres recursos de Google Cloud, copiant / enganxant la comanda següent i, a continuació, prement la tecla "Enter":
PROJECT = $ (gcloud config get-value project) gcloud projects add-iam-policy-binding $ PROJECT --member = "serviceAccount: [email protected]" --role = "papers / ml. administrador "gcloud projects add-iam-policy-binding $ PROJECT --member =" serviceAccount: [email protected] " --role =" papers / storage.admin "
Hora d'entrenament: creació del vostre conjunt de dades
Amb aquesta configuració fora del camí, ja estem preparats per carregar el nostre conjunt de dades. Això implica:
- Creació d'un conjunt de dades buit
- Importació de fotos al conjunt de dades.
- Assignant almenys una etiqueta a cada foto. AutoML Vision ignorarà completament les fotos que no tinguin cap etiqueta.
Per facilitar el procés d’etiquetatge, vaig a penjar i etiquetar totes les meves fotos de gossos abans d’afrontar les fotos del gat:
- Dirigiu-vos a la interfície d'usuari de AutoML Vision (encara en versió beta en el moment d'escriure).
- Seleccioneu "Nou conjunt de dades".
- Indiqueu un nom descriptiu al vostre conjunt de dades.
- Feu clic a "Selecciona fitxers".
- A la finestra següent, seleccioneu totes les fotografies del vostre gos i, a continuació, feu clic a "Obrir".
- Com que les nostres imatges no disposen de més d’una etiqueta, podem deixar seleccionada “Habilita la classificació de diverses etiquetes”. Feu clic a "Crea un conjunt de dades".
Una vegada finalitzada la càrrega, Cloud UML Vision UI us portarà a una pantalla que conté totes les vostres imatges, a més d'un desglossament de les etiquetes que hagueu aplicat a aquest conjunt de dades.
Com que el nostre conjunt de dades actualment només conté imatges de gossos, podem etiquetar-les en massa:
- Al menú de l'esquerra, seleccioneu "Afegeix etiqueta".
- Escriviu "gos" i després premeu la tecla "Enter" del teclat.
- Feu clic a "Selecciona totes les imatges".
- Obriu el menú desplegable "Etiqueta" i trieu "gos".

Ara hem etiquetat totes les nostres fotos de gossos, és el moment per passar a les fotos del gat:
- Seleccioneu "Afegir imatges" a la barra de capçalera.
- Trieu "Carrega des del vostre ordinador".
- Seleccioneu totes les fotografies del vostre gat i, a continuació, feu clic a "Obrir".
- Al menú de l'esquerra, seleccioneu "Afegeix etiqueta".
- Escriviu "cat" i després premeu la tecla "Enter" del teclat.
- Aneu a través i seleccioneu cada foto del gat, fent una volta sobre la imatge i feu clic a la icona de marca petita quan apareix.
- Obriu el menú desplegable "Etiqueta" i trieu "Gat".
Formació del vostre model d’aprenentatge automàtic
Ara tenim el nostre conjunt de dades, és hora de formar el nostre model. En rep un calcula hora de formació gratuïta per model fins a un màxim de 10 models cada mes, la qual cosa representa un ús intern del càlcul i, per tant, potser no es correlacionarà amb una hora real del rellotge.
Per formar el vostre model, simplement:
- Seleccioneu la pestanya "Tren" de la interfície automàtica de la interfície d'usuari de la visualització automàtica
- Feu clic a "Comença la formació".
El temps que triga Cloud AutoML Vision a formar el vostre model variarà segons la quantitat de dades que proporcioneu, tot i que segons els documents oficials hauria de trigar uns 10 minuts. Un cop format el vostre model, Cloud AutoML Vision el desplegarà automàticament i enviareu un correu electrònic que us notifiqui que el vostre model ja està preparat per utilitzar-lo.
Com de precisa és el vostre model?
Abans de posar a prova el vostre model, potser voldreu fer alguns retocs, per assegurar-vos que les prediccions siguin el més exactes possibles.
Seleccioneu la pestanya "Avalua" i, a continuació, seleccioneu un dels vostres filtres al menú de l'esquerra.

En aquest moment, la IU AutoML Vision mostrarà la informació següent per a aquesta etiqueta:
- Llindar de puntuació. Aquest és el nivell de confiança que ha de tenir el model per assignar una etiqueta a una nova foto. Podeu utilitzar aquest control lliscant per provar l'impacte que tindran uns llindars diferents en el vostre conjunt de dades, supervisant els resultats del gràfic de record de precisió que s'acompanya. Els llindars inferiors signifiquen que el model classificarà més imatges, però hi ha un risc més gran d'identificar erròniament les fotos. Si el llindar és alt, el model classificarà menys imatges, però també hauria d'identificar erròniament les imatges.
- Precisió mitjana. Així és el rendiment del vostre model a tots els llindars de puntuació, amb 1.0 la puntuació màxima.
- Precisió. Com més gran sigui la precisió, menys falsos positius hauríeu de trobar, que és on el model aplica l’etiqueta equivocada a una imatge. Un model d'alta precisió etiquetarà només els exemples més rellevants.
- Recordem De tots els exemples que haurien d’haver estat assignats una etiqueta, el record ens explica quants d’ells se’ls va assignar una etiqueta. Com més alt sigui el percentatge de recordació, menys negatius falsos hauríeu de trobar, que és en el cas que el model no etiqueta una imatge.
Posa a prova el teu model.
Ara arriba la part divertida: comprovar si el vostre model pot identificar si una foto conté un gos o un gat, generant una predicció basada en dades que no ha vist abans.
- Feu una foto que no ho era inclòs al conjunt de dades original.
- A la consola de visió automàtica, seleccioneu la pestanya "Prediu".
- Seleccioneu "Carregueu imatges".
- Trieu la imatge que voleu analitzar AutoML Vision.
- Al cap d’uns moments, el vostre model predictarà, és possible que sigui correcte!

Tingueu en compte que, mentre que la visió de Cloud AutoML és beta, pot haver-hi un retard d'escalfament amb el vostre model. Si la sol·licitud retorna un error, espereu uns segons abans de tornar-ho a provar.
Embalatge
En aquest article, analitzem com podeu utilitzar Cloud AutoML Vision per formar i implementar un model d’aprenentatge personalitzat. Creus que eines com ara AutoML poden tenir més gent que utilitza l'aprenentatge automàtic? Feu-nos-ho saber als comentaris a continuació!


